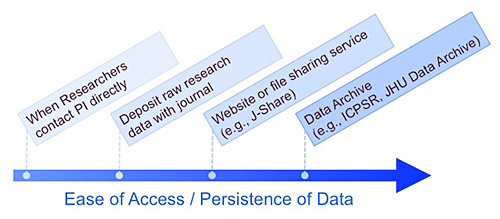
Many funders and some publishers are placing increasing importance on the sharing of research data. This trend for more access to research data will soon be increasing (see OSTP memo). As a consultant with JHU Data Management Services, I get asked by scientists how to share research data? The diagram below illustrates how research data can be shared through a variety of mechanisms, but each solution has pros and cons that researchers need to consider.
Ease of Access
Researchers need to consider how public they want to make their data. What are your funder’s or publisher’s expectations for sharing research data? How much time are you willing to devote to responding to requests for data and then responding to follow-up questions about your data? How do others in your research community share data? Please note that data with any legal/ethical restrictions on it, such as confidentiality, security, intellectual property, and privacy concerns, should not be shared.
Providing data through peer-to-peer correspondence allows scientists to retain control over who is using it and doesn’t require upfront preparation for sharing as a website or data archive would; however, the onus for finding, sending, and explaining the data remains with the scientist.
Persistence of Data
For persistence of data, researchers need to consider their ability to preserve and understand their digital research data in the future. Can you maintain multiple copies of your data? Can you ensure that, in the future, your files can be opened and are not corrupted? Will you be able to find and understand your data in three or more years?
The more time that has elapsed between when data are generated and when data are requested, the greater the probability that 1) technological problems with the data will have occurred such as loss of file integrity, and/or obsolescence of media, software, hardware, or format and 2) the ability to find and understand your data will diminish. File sharing services and repositories provide the technological infrastructure for preserving data. In addition, because data in repositories can be better organized, documented, and cited, it is easier for others to find and understand data without having to contact the scientist who generated it.
Data Repositories
Data repositories, digital systems that actively manage data, provide the most robust access and persistence services. Repositories differ in their capabilities, but most include the following to varying degrees:
- Providing a web-accessible interface for discovering and downloading research data collections.
- Managing preservation of digital objects such as file integrity checking and redundant offsite backups.
- Using identifiers, such as DOIs (digital object identifiers) to give datasets persistent location links and citations, which are more stable than URLs of websites
- Describing projects and files, and ways to include documentation sufficient for using the collection without contacting the researcher.
Search for repositories in your field on the Re3data website, or contact us for assistance in locating a suitable data repository.
In addition, while some academic disciplines have established research data repositories, many fields of research do not have easily available options for archiving and online access. At Johns Hopkins University, JHU researchers may deposit their research data into the JHU Data Archive. If you are interested in archiving your data here, please contact us at datamanagement@jhu.edu to discuss your research and data access needs.